Note
Click here to download the full example code
Sequential Forward Feature Selection (SFFS)¶
This example shows how to make a Random Sampling with 50% for each class.
Import librairies¶
from museotoolbox.ai import SequentialFeatureSelection
from museotoolbox.cross_validation import LeavePSubGroupOut
from museotoolbox import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import numpy as np
Out:
/home/docs/checkouts/readthedocs.org/user_builds/museotoolbox/conda/latest/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject
return f(*args, **kwds)
/home/docs/checkouts/readthedocs.org/user_builds/museotoolbox/conda/latest/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject
return f(*args, **kwds)
/home/docs/checkouts/readthedocs.org/user_builds/museotoolbox/conda/latest/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject
return f(*args, **kwds)
Load HistoricalMap dataset¶
X,y,g = datasets.load_historical_data(return_X_y_g=True,low_res=True)
Create CV¶
LSGO = LeavePSubGroupOut(valid_size=0.8,n_repeats=2,
random_state=12,verbose=False)
Initialize Random-Forest and metrics¶
classifier = RandomForestClassifier(random_state=12,n_jobs=1)
f1 = metrics.make_scorer(metrics.f1_score)
Set and fit the Sequentia Feature Selection¶
SFFS = SequentialFeatureSelection(classifier=classifier,param_grid=dict(n_estimators=[10,20]),verbose=False)
SFFS.fit(X.astype(np.float),y,g,cv=LSGO,max_features=3)
Show best features and score
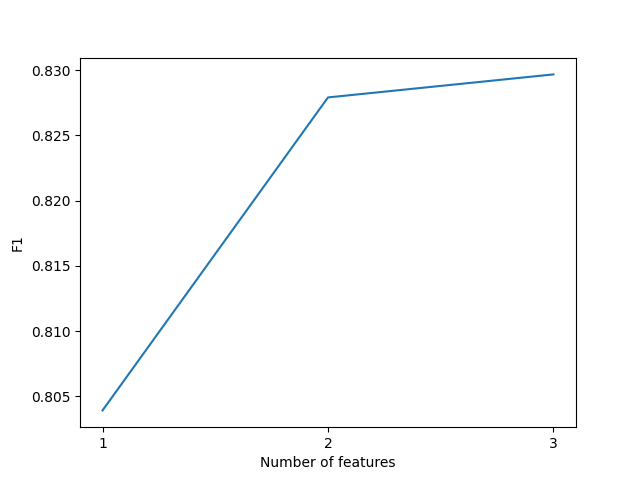
print('Best features are : '+str(SFFS.best_features_))
print('F1 are : '+str(SFFS.best_scores_))
Out:
Best features are : [2, 0, 1]
F1 are : [0.8039189318356357, 0.8279091229700823, 0.8296741254915145]
In order to predict every classification from the best feature
SFFS.predict_best_combination(datasets.load_historical_data()[0],'/tmp/SFFS/best_classification.tif')
Out:
Predict with combination 2
Total number of blocks : 15
Detected 1 band for function predict_array.
No data is set to : 0.
Batch processing (15 blocks using 11Mo of ram)
Prediction... [##......................................]6%
Prediction... [#####...................................]13%
Prediction... [########................................]20%
Prediction... [##########..............................]26%
Prediction... [#############...........................]33%
Prediction... [################........................]40%
Prediction... [##################......................]46%
Prediction... [#####################...................]53%
Prediction... [########################................]60%
Prediction... [##########################..............]66%
Prediction... [#############################...........]73%
Prediction... [################################........]80%
Prediction... [##################################......]86%
Prediction... [#####################################...]93%
Prediction... [########################################]100%
Plot example
from matplotlib import pyplot as plt
plt.plot(np.arange(1,len(SFFS.best_scores_)+1),SFFS.best_scores_)
plt.xlabel('Number of features')
plt.xticks(np.arange(1,len(SFFS.best_scores_)+1))
plt.ylabel('F1')
plt.show()
Total running time of the script: ( 0 minutes 2.709 seconds)